ChatGPT模型原理介绍¶
学习目标
- 了解ChatGPT的本质
- 了解GPT系列模型的原理和区别
1 什么是ChatGPT?¶
ChatGPT 是由人工智能研究实验室 OpenAI 在2022年11月30日发布的全新聊天机器人模型, 一款人工智能技术驱动的自然语言处理工具. 它能够通过学习和理解人类的语言来进行对话, 还能根据聊天的上下文进行互动, 真正像人类一样来聊天交流, 甚至能完成撰写邮件、视频脚本、文案、翻译、代码等任务.

数据显示, ChatGPT在推出2个多月的时间内,月活跃用户已经超过1亿, 这, 成为史上增长最快的消费者应用. 全球每天约有1300万独立访问者使用ChatGPT, 而爆炸性的增量也给该公司发展带来了想象空 间.
自从 ChatGPT 出现后. 突然之间, 每个人都在谈论人工智能如何颠覆他们的工作、公司、学校和生活. 那么ChatGPT背后的实现原理是什么呢?接下来我们将给大家进行详细的解析.
在我们了解ChatGPT模型原理之前, 需要回顾下ChatGPT的成长史, 即我们需要对GPT-1、GPT-2、GPT-3等一系列模型进行了解和学习, 以便我们更好的理解ChatGPT的算法原理.
2 GPT-1介绍¶
2018年6月, OpenAI公司发表了论文“Improving Language Understanding by Generative Pre-training”《用生成式预训练提高模型的语言理解力》, 推出了具有1.17亿个参数的GPT-1(Generative Pre-training , 生成式预训练)模型.
与BERT最大的区别在于GPT-1采用了传统的语言模型方法进行预训练, 即使用单词的上文来预测单词, 而BERT是采用了双向上下文的信息共同来预测单词.
正是因为训练方法上的区别, 使得GPT更擅长处理自然语言生成任务(NLG), 而BERT更擅长处理自然语言理解任务(NLU).
2.1 GPT-1模型架构¶
看三个语言模型的对比架构图, 中间的就是GPT-1:
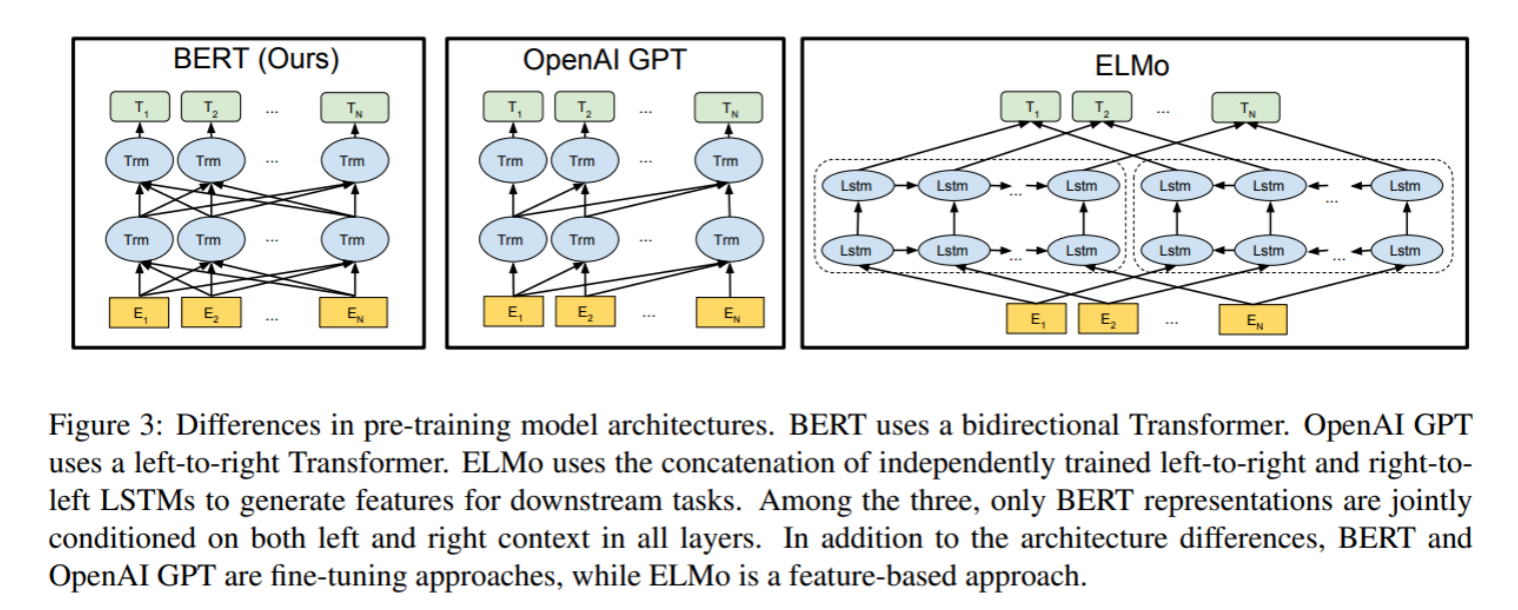
从上图可以很清楚的看到GPT采用的是单向Transformer模型, 例如给定一个句子[u1, u2, ..., un], GPT在预测单词ui的时候只会利用[u1, u2, ..., u(i-1)]的信息, 而BERT会同时利用上下文的信息[u1, u2, ..., u(i-1), u(i+1), ..., un].
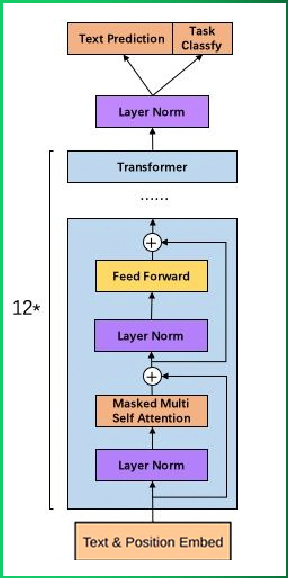
作为两大模型的直接对比, BERT采用了Transformer的Encoder模块, 而GPT采用了Transformer的Decoder模块. 并且GPT的Decoder Block和经典Transformer Decoder Block还有所不同, 如下图所示:
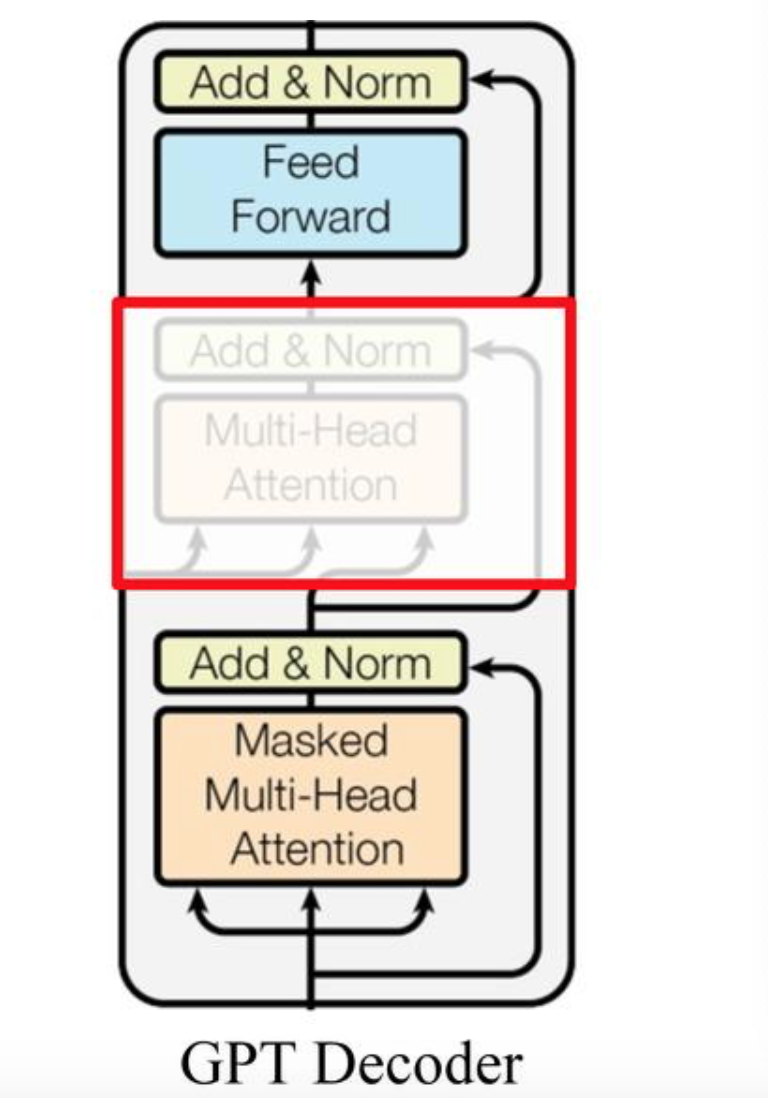
如上图所示, 经典的Transformer Decoder Block包含3个子层, 分别是Masked Multi-Head Attention层, encoder-decoder attention层, 以及Feed Forward层. 但是在GPT中取消了第二个encoder-decoder attention子层, 只保留Masked Multi-Head Attention层, 和Feed Forward层.
注意: 对比于经典的Transformer架构, 解码器模块采用了6个Decoder Block; GPT的架构中采用了12个Decoder Block.
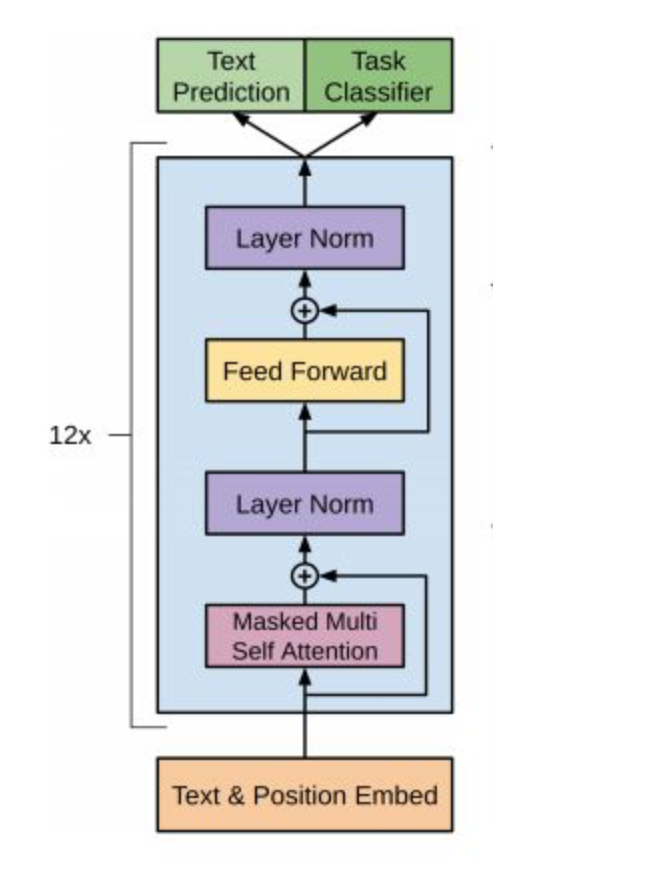
2.2 GPT-1训练过程¶
GPT-1的训练包括两阶段过程: 预训练 + 微调 - 第一阶段: 无监督的预训练语言模型. - 第二阶段: 有监督的下游任务fine-tunning.
2.2.1 无监督的预训练语言模型¶
- 给定句子U = [u1, u2, ..., un], GPT训练语言模型时的目标是最大化下面的似然函数:
- 上述公式具体来说是要预测每个词ui的概率,这个概率是基于它前面 ui-k 到 ui−1 个词,以及模型 Θ。这里的 k 表示上文的窗口大小,理论上来讲 k 取的越大,模型所能获取的上文信息越充足,模型的能力越强。
- GPT是一个单向语言模型,模型对输入U 进行特征嵌入得到 transformer 第一层的输h0,再经过多层 transformer 特征编码,使用最后一层的输出即可得到当前预测的概率分布,计算过程如下:
其中Wp是单词的位置编码, We是单词本身的word embedding. Wp的形状是[max_seq_len, embedding_dim], We的形状是[vocab_size, embedding_dim].
- 得到输入张量h0后, 要将h0传入GPT的Decoder Block中, 依次得到ht:
- 最后通过得到的ht来预测下一个单词:
2.2.2 有监督的下游任务fine-tunning¶
- GPT经过预训练后, 会针对具体的下游任务对模型进行微调. 微调采用的是有监督学习, 训练样本包括单词序列[x1, x2, ..., xn]和label y. GPT微调的目标任务是根据单词序列[x1, x2, ..., xn]预测标签y.
其中W_y表示预测输出的矩阵参数, 微调任务的目标是最大化下面的函数:
- 综合两个阶段的目标任务函数, 可知GPT的最终优化函数为:
2.2.3 整体训练过程架构图¶
根据下游任务适配的过程分两步: 1、根据任务定义不同输入, 2、对不同任务增加不同的分类层.
具体定义可以参见下图:
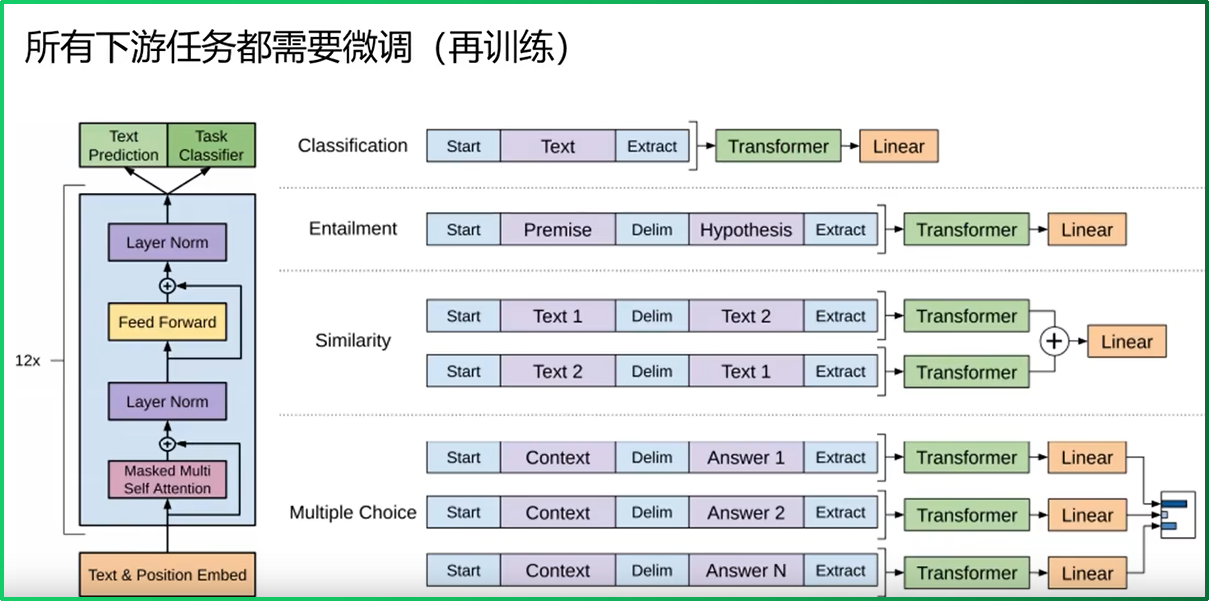
- 分类任务(Classification): 将起始和终止token加入到原始序列两端, 输入transformer中得到特征向量, 最后经过一个全连接得到预测的概率分布;
- 文本蕴涵(Entailment): 将前提(premise)和假设(hypothesis)通过分隔符(Delimiter)隔开, 两端加上起始和终止token. 再依次通过transformer和全连接得到预测结果;
- 文本相似度(Similarity): 输入的两个句子, 正向和反向各拼接一次, 然后分别输入给transformer, 得到的特征向量拼接后再送给全连接得到预测结果;
- 问答和常识推理(Multiple-Choice): 将 N个选项的问题抽象化为N个二分类问题, 即每个选项分别和内容进行拼接, 然后各送入transformer和全连接中, 最后选择置信度最高的作为预测结果
总的来说,都是通过在序列前后添加 Start 和 Extract 特殊标识符来表示开始和结束,序列之间添加必要的 Delim 标识符来表示分隔,当然实际使用时不会直接用 “Start/Extract/Delim” 这几个词,而是使用某些特殊符号。基于不同下游任务构造的输入序列,使用预训练的 GPT 模型进行特征编码,然后使用序列最后一个 token 的特征向量进行预测。
可以看到,不论下游任务的输入序列怎么变,最后的预测层怎么变,中间的特征抽取模块都是不变的,具有很好的迁移能力。
2.3 GPT-1数据集¶
GPT-1使用了BooksCorpus数据集, 文本大小约 5 GB,包含 7400w+ 的句子。这个数据集由 7000 本独立的、不同风格类型的书籍组成, 选择该部分数据集的原因: - 书籍文本包含大量高质量长句,保证模型学习长距离信息依赖。 - 这些书籍因为没有发布, 所以很难在下游数据集上见到, 更能验证模型的泛化能力.
2.4 GPT-1模型的特点¶
模型的一些关键参数为:
| 参数 | 取值 |
|---|---|
| transformer 层数 | 12 |
| 特征维度 | 768 |
| transformer head 数 | 12 |
| 总参数量 | 1.17 亿 |
优点:
-
在有监督学习的12个任务中, GPT-1在9个任务上的表现超过了state-of-the-art的模型
-
利用Transformer做特征抽取, 能够捕捉到更长的记忆信息, 且较传统的 RNN 更易于并行化
缺点:
-
GPT 最大的问题就是传统的语言模型是单向的.
-
针对不同的任务, 需要不同的数据集进行模型微调, 相对比较麻烦
2.5 GPT-1模型总结¶
- GPT-1证明了transformer对学习词向量的强大能力, 在GPT-1得到的词向量基础上进行下游任务的学习, 能够让下游任务取得更好的泛化能力. 对于下游任务的训练, GPT-1往往只需要简单的微调便能取得非常好的效果.
- GPT-1在未经微调的任务上虽然也有一定效果, 但是其泛化能力远远低于经过微调的有监督任务, 说明了GPT-1只是一个简单的领域专家, 而非通用的语言学家.
3 GPT-2介绍¶
2019年2月, OpenAI推出了GPT-2, 同时, 他们发表了介绍这个模型的论文“Language Models are Unsupervised Multitask Learners” (语言模型是无监督的多任务学习者).
相比于GPT-1, GPT-2突出的核心思想为多任务学习, 其目标旨在仅采用无监督预训练得到一个泛化能力更强的语言模型, 直接应用到下游任务中. GPT-2并没有对GPT-1的网络结构进行过多的创新与设计, 而是使用了更多的网络参数与更大的数据集: 最大模型共计48层, 参数量达15亿.
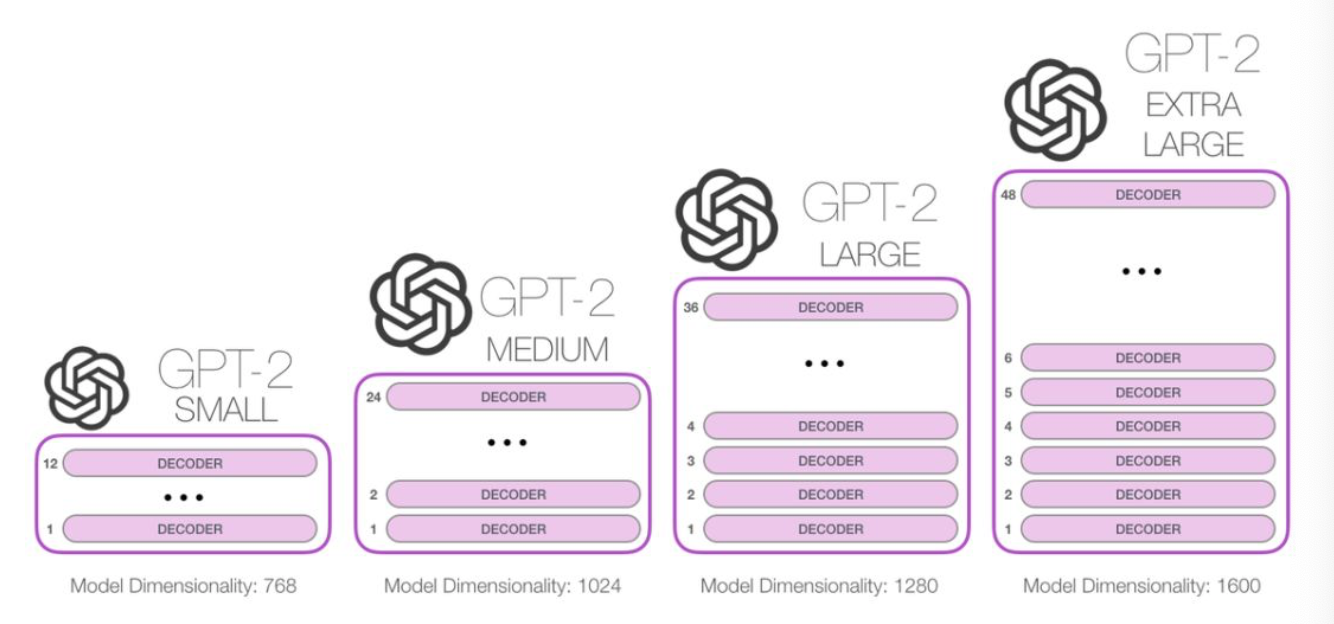
3.1 GPT-2模型架构¶
在模型方面相对于 GPT-1 来说GPT-2做了微小的改动:
- LN层被放置在Self-Attention层和Feed Forward层前, 而不是像原来那样后置(目的:随着模型层数不断增加,梯度消失和梯度爆炸的风险越来越大,这些调整能够**减少预训练过程中各层之间的方差变化,使梯度更加稳定**)
- 在最后一层Tansfomer Block后增加了LN层
- 输入序列的最大长度从 512 扩充到 1024;
3.2 GPT-2训练核心思想¶
目前大部分 NLP 模型是结合无监督的 Pre-training 和监督学习的 Fune-tuning, 但这种方法的缺点是针对某特定任务需要不同类型标注好的训练数据. GPT-2的作者认为这是狭隘的专家而不是通才, 因此该作者希望能够通过无监督学习训练出一个可以应对多种任务的通用系统.
标题中的多任务学习与我们常规理解的有监督学习中的多任务不太一样,这里主要是指模型从大规模数据中学到的能力能够直接在多个任务之间进行迁移,而不需要额外提供特定任务的数据,因此引出了 GPT-2 的主要观点:zero-shot。通过 zero-shot,在迁移到其他任务上的时候不需要额外的标注数据,也不需要额外的模型训练。
因此, GPT-2的训练去掉了Fune-tuning只包括无监督的预训练过程, 和GPT-1第一阶段训练一样, 也属于一个单向语言模型
理解GPT-2模型的学习目标: 使用无监督的预训练模型做有监督的任务.
-
语言模型其实也是在给序列的条件概率建模, 即p(sn|s1,s2,...,sn−1)
-
在 GPT-1 中,下游任务需要对不同任务的输入序列进行改造,在序列中加入了开始符、分隔符和结束符之类的特殊标识符,但是在 zero-shot 前提下,我们无法根据不同的下游任务去添加这些标识符,因为不进行额外的微调训练,模型在预测的时候根本不认识这些特殊标记。所以在 zero-shot 的设定下,不同任务的输入序列应该与训练时见到的文本长得一样,也就是以自然语言的形式去作为输入,例如下面两个任务的输入序列是这样改造的:
机器翻译任务:translate to french, { english text }, { french text } 阅读理解任务:answer the question, { document }, { question }, { answer }
- 为什么上述输入序列的改造是有效的?或者说为什么 zero-shot 是有效的?这里引用原文的一句话:
Our approach motivates building as large and diverse a dataset as possible in order to collect natural language demonstrations of tasks in as varied of domains and contexts as possible.
- 大概意思是,从一个尽可能大且多样化的数据集中一定能收集到不同领域不同任务相关的自然语言描述示例,例如下图中展示了英法互译任务在自然语言中出现的示例,表明了不同任务的任务描述在语料中真实存在:

- 所以 GPT-2 的核心思想就是,当模型的容量非常大且数据量足够丰富时,仅仅靠语言模型的学习便可以完成其他有监督学习的任务,不需要在下游任务微调。
综上, GPT-2的核心思想概括为: 任何有监督任务都是语言模型的一个子集, 当模型的容量非常大且数据量足够丰富时, 仅仅靠训练语言模型的学习便可以完成其他有监督学习的任务.
3.3 GPT-2的数据集¶
为了保证 zero-shot 的效果,必须要足够大且覆盖面广。所以 GPT-2 专门爬取了大量的网络文本数据,GPT-2的文章取自于Reddit上高赞的文章, 命名为WebText. 数据集共有约800万篇文章, 累计体积约40G. 为了避免和测试集的冲突, WebText移除了涉及Wikipedia的文章.
3.4 GPT-2模型的特点¶
与GPT-1的区别:
- 主推 zero-shot,而 GPT-1 为 pre-train + fine-tuning;
- 训练数据规模更大,GPT-2 为 800w 文档 40G,GPT-1 为 5GB;
- 模型大小,GPT-2 最大 15 亿参数,GPT-1为 1 亿参数;
- 模型结构调整,层归一化;
- 训练参数,batch_size 从 64 增加到 512,上文窗口大小从 512 增加到 1024,等等;
优点:
-
文本生成效果好, 在8个语言模型任务中, 仅仅通过zero-shot学习, GPT-2就有7个超过了state-of-the-art的方法.
-
海量数据和大量参数训练出来的词向量模型有迁移到其它类别任务中而不需要额外的训练.
缺点:
-
无监督学习能力有待提升
-
有些任务上的表现不如随机
3.5 GPT-2模型总结¶
GPT-2的最大贡献是验证了通过海量数据和大量参数训练出来的词向量模型有迁移到其它类别任务中而不需要额外的训练. 但是很多实验也表明, GPT-2的无监督学习的能力还有很大的提升空间, 甚至在有些任务上的表现不比随机的好. 尽管在有些zero-shot的任务上的表现不错, 但是我们仍不清楚GPT-2的这种策略究竟能做成什么样子. GPT-2表明随着模型容量和数据量的增大, 其潜能还有进一步开发的空间, 基于这个思想, 诞生了我们下面要介绍的GPT-3.
4 GPT-3介绍¶
2020年5月, OpenAI发布了GPT-3, 同时发表了论文“Language Models are Few-Shot Learner”《小样本学习者的语言模型》.
通过论文题目可以看出:GPT-3 不再去追求那种极致的不需要任何样本就可以表现很好的模型,而是考虑像人类的学习方式那样,仅仅使用**极少数样本**就可以掌握某一个任务,但是这里的 few-shot 不是像之前的方式那样,使用少量样本在下游任务上去做微调,因为在 GPT-3 那样的参数规模下,即使是参数微调的成本也是高到无法估计。
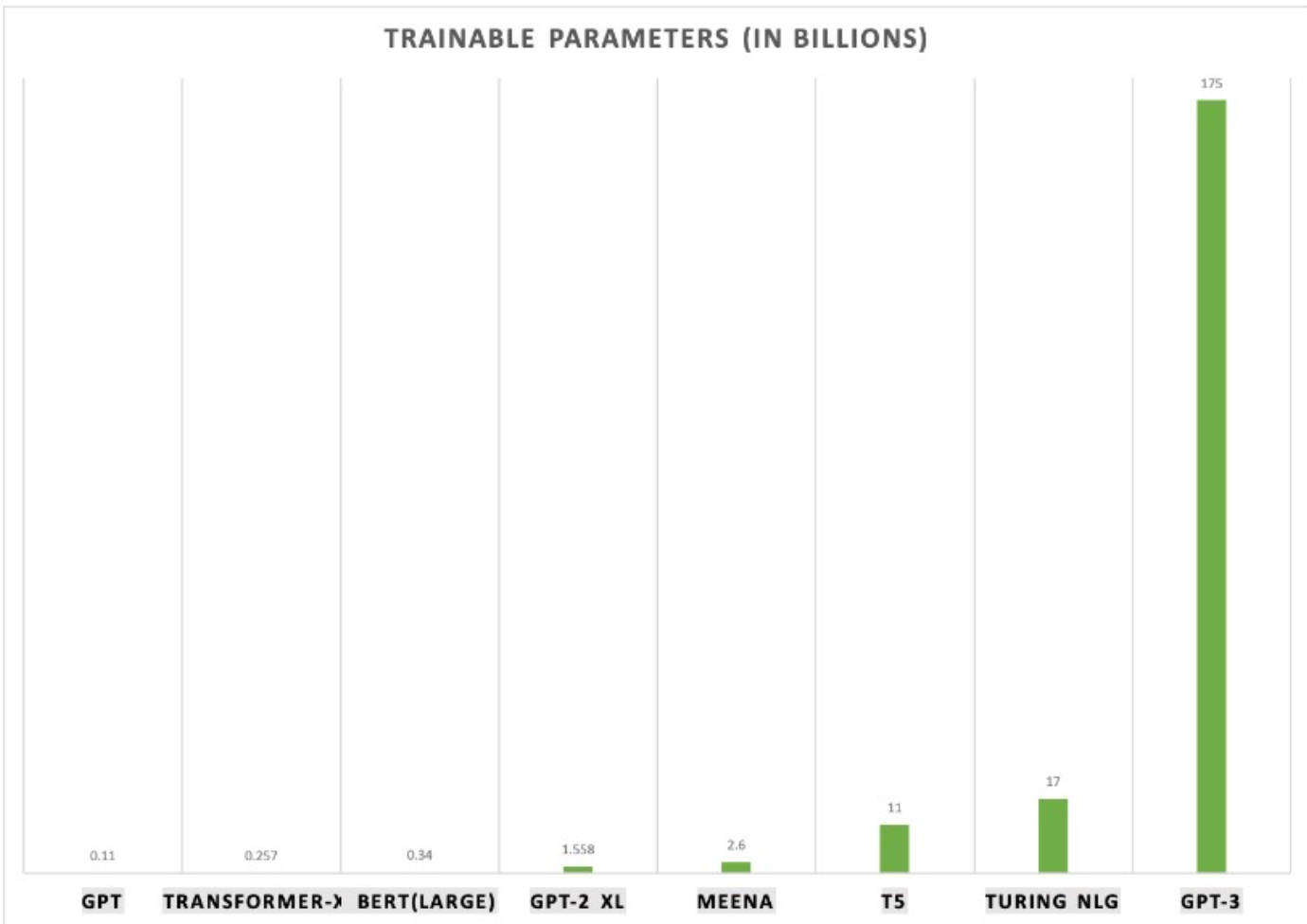
GPT-3 作为其先前语言模型 (LM) GPT-2 的继承者. 它被认为比GPT-2更好、更大. 事实上, 与他语言模型相比, OpenAI GPT-3 的完整版拥有大约 1750 亿个可训练参数, 是迄今为止训练的最大模型, 这份 72 页的研究论文 非常详细地描述了该模型的特性、功能、性能和局限性.
下图为不同模型之间训练参数的对比:
4.1 GPT-3模型架构¶
实际上GPT-3 不是一个单一的模型, 而是一个模型系列. 系列中的每个模型都有不同数量的可训练参数. 下表显示了每个模型、体系结构及其对应的参数:
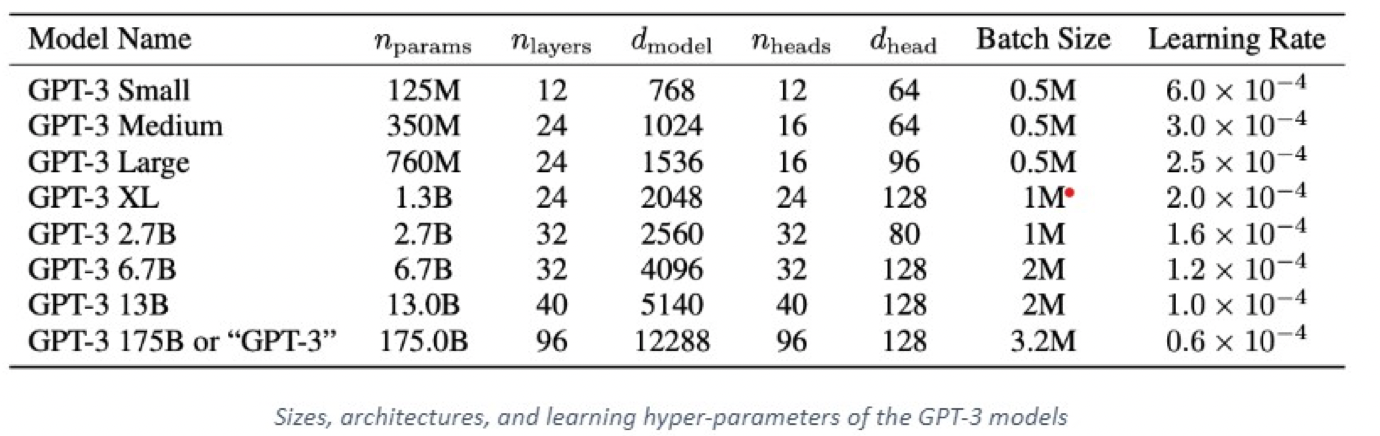
其中最大版本 GPT-3 175B 或“GPT-3”具有175个B参数、96层的多头Transformer、Head size为96、词向量维度为12288、文本长度大小为2048.
4.2 GPT-3训练核心思想¶
GPT-3模型训练的思想与GPT-2的方法相似, 去除了fine-tune过程, 只包括预训练过程, 不同只在于采用了参数更多的模型、更丰富的数据集和更长的训练的过程.
但是GPT-3 模型在进行下游任务评估和预测时采用了三种方法, 他们分别是: Few-shot、One-shot、Zero-shot.
其中 Few-shot、One-shot也被称之为情境学习(in-context learning,也可称之为提示学习). 情境学习理解: 在被给定的几个任务示例或一个任务说明的情况下, 模型应该能通过简单预测以补全任务中其他的实例. 即情境学习要求预训练模型要对任务本身进行理解.
In-context learnin核心思想在于通过少量的数据寻找一个合适的初始化范围,使得模型能够在有限的数据集上快速拟合,并获得不错的效果。
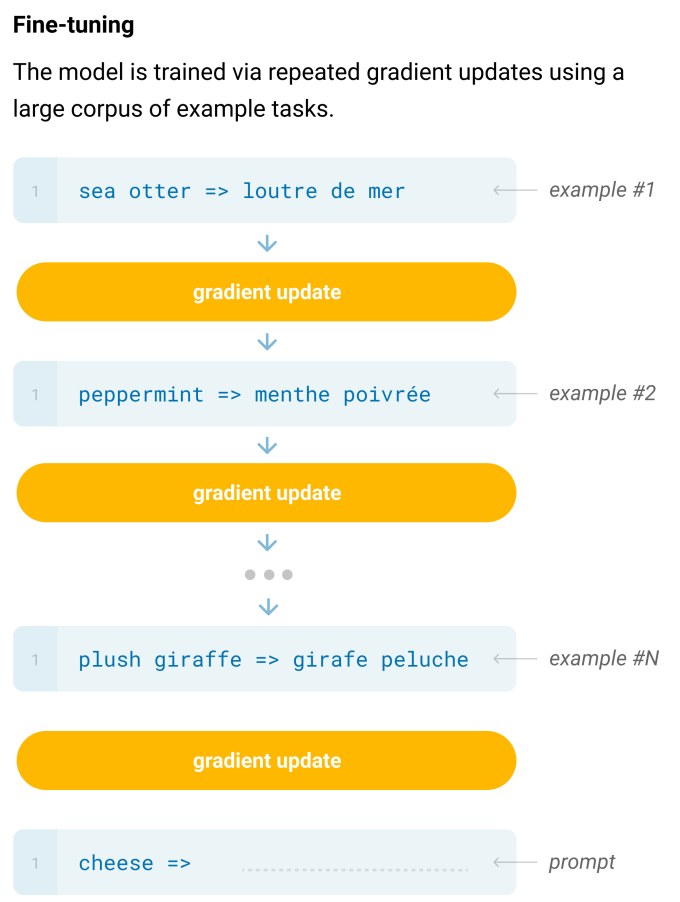
下面以从“英语到法语的翻译任务”为例, 分别对比传统的微调策略和GPT-3三种情景学习方式.
- 下图是传统的微调策略:
-
传统的微调策略存在问题:
-
微调需要对每一个任务有一个任务相关的数据集以及和任务相关的微调.
- 需要一个相关任务大的数据集, 而且需要对其进行标注
- 当一个样本没有出现在数据分布的时候, 泛化性不见得比小模型要好
下图显示了 GPT-3 三种情景学习方法:

- zero-shot learning
- 定义: 给出任务的描述, 然后提供测试数据对其进行预测, 直接让预训练好的模型去进行任务测试.
- 示例: 向模型输入“这个任务要求将中文翻译为英文. 销售->”, 然后要求模型预测下一个输出应该是什么, 正确答案应为“sell”
- one-shot learning
- 定义: 在预训练和真正翻译的样本之间, 插入一个样本做指导. 相当于在预训练好的结果和所要执行的任务之间, 给一个例子, 告诉模型英语翻译为法语, 应该这么翻译.
- 示例: 向模型输入“这个任务要求将中文翻译为英文. 你好->hello, 销售->”, 然后要求模型预测下一个输出应该是什么, 正确答案应为“sell”.
- few-shot learning
- 定义: 在预训练和真正翻译的样本之间, 插入多个样本做指导. 相当于在预训练好的结果和所要执行的任务之间, 给多个例子, 告诉模型应该如何工作.
-
示例: 向模型输入“这个任务要求将中文翻译为英文. 你好->hello, 再见->goodbye, 购买->purchase, 销售->”, 然后要求模型预测下一个输出应该是什么, 正确答案应为“sell”.
-
总之: in-context learning,虽然它与 fine-tuning 一样都需要一些有监督标注数据,但是两者的区别是:
- 【本质区别】fine-tuning 基于标注数据对模型参数进行更新,而 in-context learning 使用标注数据时不做任何的梯度回传,模型参数不更新;
- in-context learning 依赖的数据量(10~100)远远小于 fine-tuning 一般的数据量;
最终通过大量下游任务实验验证,Few-shot 效果最佳,One-shot 效果次之,Zero-shot 效果最差:
4.3 GPT-3数据集¶
一般来说, 模型的参数越多, 训练模型所需的数据就越多. GPT-3共训练了5个不同的语料大约 45 TB 的文本数据, 分别是低质量的Common Crawl(需要数据清洗), 高质量的WebText2, Books1, Books2和Wikipedia, GPT-3根据数据集的不同的质量赋予了不同的权值, 权值越高的在训练的时候越容易抽样到, 如下表所示.
| 数据集 | 数量(tokens) | 训练数据占比 |
|---|---|---|
| Common Crawl(filterd) | 4100亿 | 60% |
| Web Text2 | 190亿 | 22% |
| BOOK1 | 120亿 | 8% |
| BOOK2 | 550亿 | 8% |
| Wikipedia | 30亿 | 2% |
不同数据的介绍:
-
Common Crawl语料库包含在 8 年的网络爬行中收集的 PB 级数据. 语料库包含原始网页数据、元数据提取和带有光过滤的文本提取.
-
WebText2是来自具有 3+ upvotes 的帖子的所有出站 Reddit 链接的网页文本.
- Books1和Books2是两个基于互联网的图书语料库.
- 英文维基百科页面 也是训练语料库的一部分.
4.4 GPT-3模型的特点¶
与 GPT-2 的区别
- 效果上,超出 GPT-2 非常多,能生成人类难以区分的新闻文章;
主推 few-shot,相比于 GPT-2 的 zero-shot,具有很强的创新性;
**模型结构**略微变化,采用 sparse attention 模块;
- 海量训练语料 45TB(清洗后 570GB),相比于 GPT-2 的 40GB;
- 海量模型参数,最大模型为 1750 亿,GPT-2 最大为 15 亿参数;
优点:
-
整体上, GPT-3在zero-shot或one-shot设置下能取得尚可的成绩, 在few-shot设置下有可能超越基于fine-tune的SOTA模型.
-
去除了fune-tuning任务.
缺点:
-
由于40TB海量数据的存在, 很难保证GPT-3生成的文章不包含一些非常敏感的内容
-
对于部分任务比如: “填空类型”等, 效果具有局限性
- 当生成文本长度较长时,GPT-3 还是会出现各种问题,比如重复生成一段话,前后矛盾,逻辑衔接不好等等;
- 成本太大
4.5 GPT-3模型总结¶
GPT系列从1到3, 通通采用的是transformer架构, 可以说模型结构并没有创新性的设计. GPT-3的本质还是通过海量的参数学习海量的数据, 然后依赖transformer强大的拟合能力使得模型能够收敛. 得益于庞大的数据集, GPT-3可以完成一些令人感到惊喜的任务, 但是GPT-3也不是万能的, 对于一些明显不在这个分布或者和这个分布有冲突的任务来说, GPT-3还是无能为力的.
5 ChatGPT介绍¶
ChatGPT是一种基于GPT-3的聊天机器人模型. 它旨在使用 GPT-3 的语言生成能力来与用户进行自然语言对话. 例如, 用户可以向 ChatGPT 发送消息, 然后 ChatGPT 会根据消息生成一条回复.
GPT-3 是一个更大的自然语言处理模型, 而 ChatGPT 则是使用 GPT-3 来构建的聊天机器人. 它们之间的关系是 ChatGPT 依赖于 GPT-3 的语言生成能力来进行对话.
目前基于ChatGPT的论文并没有公布, 因此接下来我们基于openai官网的介绍对其原理进行解析
5.1 ChatGPT原理¶
在介绍ChatGPT原理之前, 请大家先思考一个问题: “模型越大、参数越多, 模型的效果就越好么啊?”. 这个答案是否定的, 因为模型越大可能导致结果越专一, 但是这个结果有可能并不是我们期望的. 这也称为大型语言模型能力不一致问题. 在机器学习中, 有个重要的概念: “过拟合”, 所谓的过拟合, 就是模型在训练集上表现得很好, 但是在测试集表现得较差, 也就是说模型在最终的表现上并不能达到我们的预期, 这就是模型能力不一致问题.
原始的 GPT-3 就是非一致模型, 类似GPT-3 的大型语言模型都是基于来自互联网的大量文本数据进行训练, 能够生成类似人类的文本, 但它们可能并不总是产生符合人类期望的输出.
ChatGPT 为了解决模型的不一致问题, 使用了人类反馈来指导学习过程, 对其进行了进一步训练. 所使用的具体技术就是强化学习(RLHF) .
5.2 什么是强化学习¶
强化学习(Reinforcement Learning, RL), 又称再励学习、评价学习或增强学习, 是机器学习方法的一种, 用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题.
强化学习的关键信息:
-
一种机器学习方法
-
关注智能体与环境之间的交互
- 目标是追求最大回报
强化学习的架构
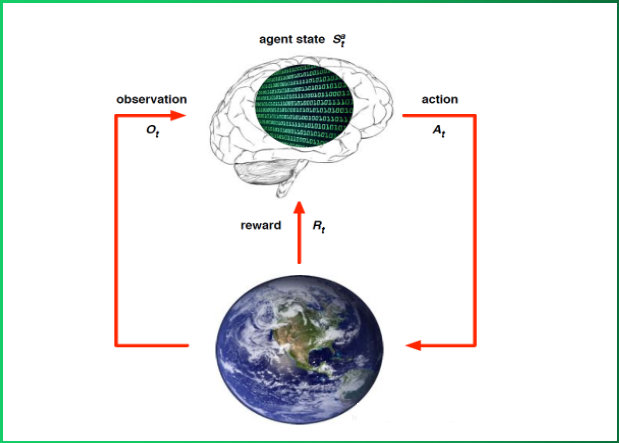
- 下图是强化学习的基本流程整体架构, 其中大脑指代智能体agent, 地球指代环境environment, 从当前的状态St出发, 在做出一个行为At 之后, 对环境产生了一些影响, 它首先给agent反馈了一个奖励信号Rt然后给agent反馈一个新的环境状态, 此处用Ot 表示, 进而融汇进入一个新的状态, agent再做出新的行为, 形成一个循环.
理解强化学习基本要素
- 这里我们以一个简单小游戏flappy bird为代表为大家讲解强化学习的基本要素:

-
Agent(智能体): 强化学习训练的主体就是Agent, 统称为“智能体”. 这里小鸟就是Agent.
-
Environment(环境): 整个游戏的大背景就是环境;超级玛丽中Agent、地面、柱子组成了整个环境.
-
State(状态): 当前 Environment和Agent所处的状态, 因为小鸟一直在移动, 分数数目也在不停变化, Agent的位置也在不停变化, 所以整个State处于变化中.
-
Policy(策略): Policy的意思就是根据观测到的状态来进行决策, 来控制Agent运动. 即基于当前的State, Agent可以采取哪些Action, 比如向上或者向下. 在数学上Policy一般定义为函数π(深度学习中Policy可以定义为一个模型), 这个policy函数π是个概率密度函数: $$ π(a|s) = P(A=a|S=s) $$
-
Reward(奖励): Agent在当前State下, 采取了某个特定的Action后, 会获得环境的一定反馈(或奖励)就是Reward. 比如: 小鸟顺利通过柱子获得奖励R=+1,如果赢了这场游戏奖励R=+10000, 我们应该把打赢游戏的奖励定义的大一些, 这样才能激励学到的policy打赢游戏而不是一味的加分, 如果小鸟碰到柱子, 小鸟就会死, 游戏结束, 这时奖励就设R=-10000, 如果这一步什么也没发生, 奖励就是R=0, 强化学习的目标就是使获得的奖励总和尽量要高.
如何让AI实现自动打游戏?
-
第一步: 通过强化学习(机器学习方法)学出Policy函数, 该步骤目的是用Policy函数来控制Agent.
-
第二步: 获取当前状态为s1, 并将s1带入Policy函数来计算概率, 从概率结果中抽样得到a1, 同时环境生成下一状态s2, 并且给Agent一个奖励r1.
- 第三步: 将新的状态s2带入Policy函数来计算概率, 抽取结果得到新的动作a2、状态s3、奖励r2.
- 第四步: 循环2-3步骤, 直到打赢游戏或者game over, 这样我们就会得到一个游戏的trajectory(轨迹), 这个轨迹是每一步的状态, 动作, 奖励.
5.3 ChatGPT强化学习步骤¶
从人类反馈中进行强化学习, 该方法总体上包括三个步骤:
-
步骤1: 监督学习, 预训练的语言模型在少量已标注的数据上进行调优, 以学习从给定的 prompt 列表生成输出的有监督的策略(即 SFT 模型);
-
步骤2: 训练奖励模型(reward): 标注者们对相对大量的 SFT 模型输出结果进行收集并排序, 这就创建了一个由比较数据组成的新数据集. 在此数据集上训练新模型, 被称为训练奖励模型(Reward Model, RM);
-
步骤3: 强化学习(PPO算法): RM 模型用于进一步调优和改进 SFT 模型, PPO 输出结果的是策略模式.
-
步骤 1 只进行一次, 而步骤 2 和步骤 3 可以持续重复进行: 在当前最佳策略模型上收集更多的比较数据, 用于训练新的 RM 模型, 然后训练新的策略. 接下来, 将对每一步的细节进行详述.
5.4 监督调优模型¶
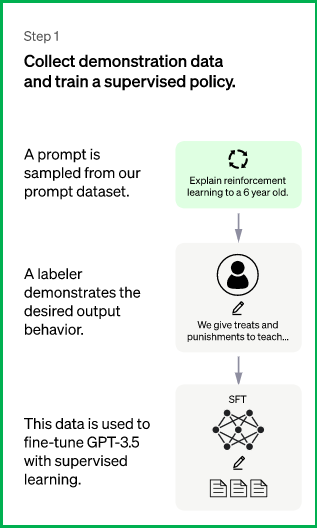
工作原理:
-
第一步是收集数据, 以训练有监督的策略模型.
-
数据收集: 选择一个提示列表, 标注人员按要求写下预期的输出. 对于 ChatGPT, 使用了两种不同的 prompt 来源: 一些是直接使用标注人员或研究人员准备的, 另一些是从 OpenAI 的 API 请求(即从 GPT-3 用户那里)获取的. 虽然整个过程缓慢且昂贵, 但最终得到的结果是一个相对较小、高质量的数据集, 可用于调优预训练的语言模型.
- 模型选择: ChatGPT 的开发人员选择了 GPT-3.5 系列中的预训练模型, 而不是对原始 GPT-3 模型进行调优. 使用的基线模型是最新版的 text-davinci-003(通过对程序代码调优的 GPT-3 模型)
由于此步骤的数据量有限, 该过程获得的 SFT 模型可能会输出仍然并非用户关注的文本, 并且通常会出现不一致问题. 这里的问题是监督学习步骤具有高可扩展性成本.
为了克服这个问题, 使用的策略是让人工标注者对 SFT 模型的不同输出进行排序以创建 RM 模型, 而不是让人工标注者创建一个更大的精选数据集.
5.5 训练奖励模型¶
这一步的目标是直接从数据中学习目标函数. 该函数的目的是为 SFT 模型输出进行打分, 这代表这些输出对于人类来说可取程度有多大. 这强有力地反映了选定的人类标注者的具体偏好以及他们同意遵循的共同准则. 最后, 这个过程将从数据中得到模仿人类偏好的系统.
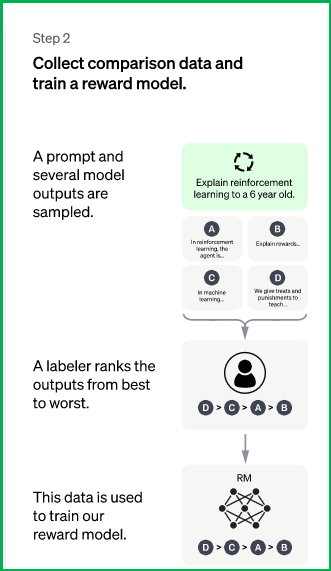
工作原理:
- 从问题库中选择问题(prompt), SFT 模型为每个 prompt 生成多个输出(4 到 9 之间的任意值)
- 标注者将输出从最佳到最差排序. 结果是一个新的标签数据集, 该数据集的大小大约是用于 SFT 模型的精确数据集的 10 倍;
- 此新数据用于训练 RM 模型 . 该模型将 SFT 模型输出作为输入, 并按优先顺序对它们进行排序.
- 模型选择: RM模型是GPT-3的蒸馏版本(参数量为6亿), 目的是通过该训练模型得到一个预测值(得分), 模型损失函数为下图表示:
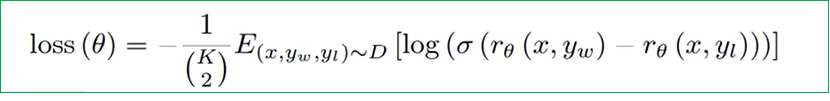
-
公式参数解析: x代表prompt原始输入, yw代表SFT模型输出的得分较高的结果, yl代表SFT模型输出得分较低的结果, rθ代表RM模型即GPT-3模型, σ代表sigmoid函数, K代表SFT 模型为每个 prompt 生成多个输出, 这里K个任选2个来模型训练.
5.6 强化学习模型¶
这一步里强化学习被应用于通过优化 RM 模型来调优 SFT 模型. 所使用的特定算法称为近端策略优化(PPO, Proximal Policy Optimization), 而调优模型称为近段策略优化模型.
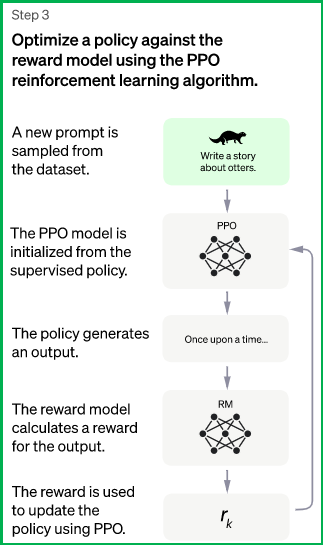
工作原理: (明确任务: 模型是通过RL来更新)
- 第一步: 输入prompt(指代问题)
- 第二步: 将prompt输入强化学习模型 (这里直接也可以理解为ChatGPT模型【监督学习微调后的】), 得到一个输出结果
- 第三步: 将第二步得到的结果输入到RM奖励模型中, 然后得到一个奖励分数. 生成的分数会基于PPO算法优化强化学习模型。比如:如果奖励分数比较低, 代表ChatGPT模型输出结果不对, 此时需要利用PPO算法更新ChatGPT模型参数
- 第四步: 循环上述步骤, 不断更新ChatGPT、RM模型.
5.7 ChatGPT特点¶
优点:
-
回答理性又全面, ChatGPT更能做到多角度全方位回答
-
降低学习成本, 可以快速获取问题答案
缺点:
-
ChatGPT 服务不稳定
-
容易一本正经的"胡说八道"
6 小结¶
- 本章节主要讲述了ChatGPT的发展历程,重点对比了N-gram语言模型和神经网络语言模型的区别,以及GPT系列模型的对比.